ไม่รู้จะเริ่มต้นใช้ AI อย่างไร?
อย่าเสี่ยงทดลองเองในยุคสงครามข้อมูล
และอย่าเสี่ยงให้ข้อมูลองค์กรรั่วไหลหรือผิดกฎหมายโดยไม่รู้ตัว
Pakpao Siam คือผู้พัฒนาระบบ AI โดยทีมคนไทย
ที่มีความเชี่ยวชาญในการออกแบบ AI Infrastructure
ปลอดภัย
ตรวจสอบได้
สอดคล้องข้อกำหนดทางกฎหมาย
เพื่อให้องค์กรใช้งาน AI ได้อย่างมั่นใจและมีประสิทธิภาพสูงสุดในระดับองค์กร
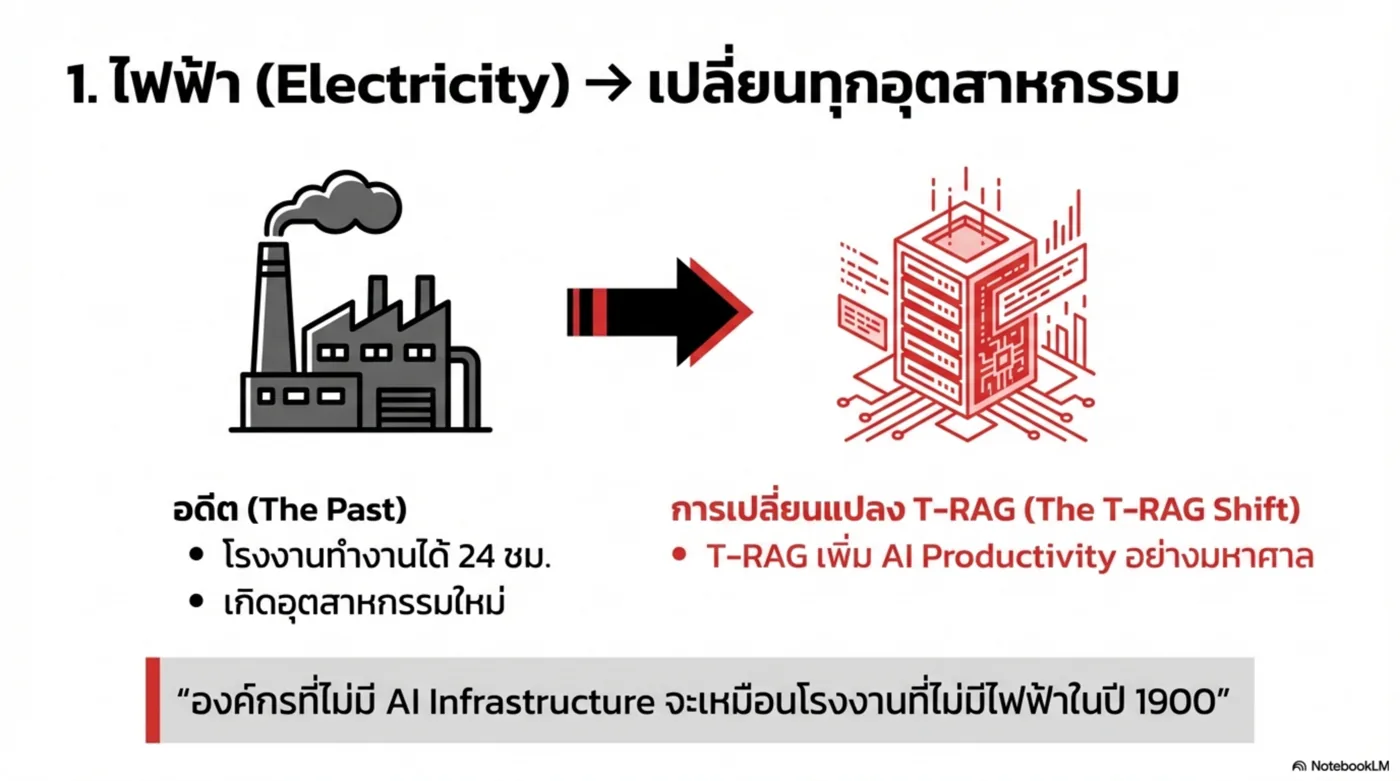
AI ไม่ใช่แค่ Software…
AI คือ Infrastructure ขององค์กร
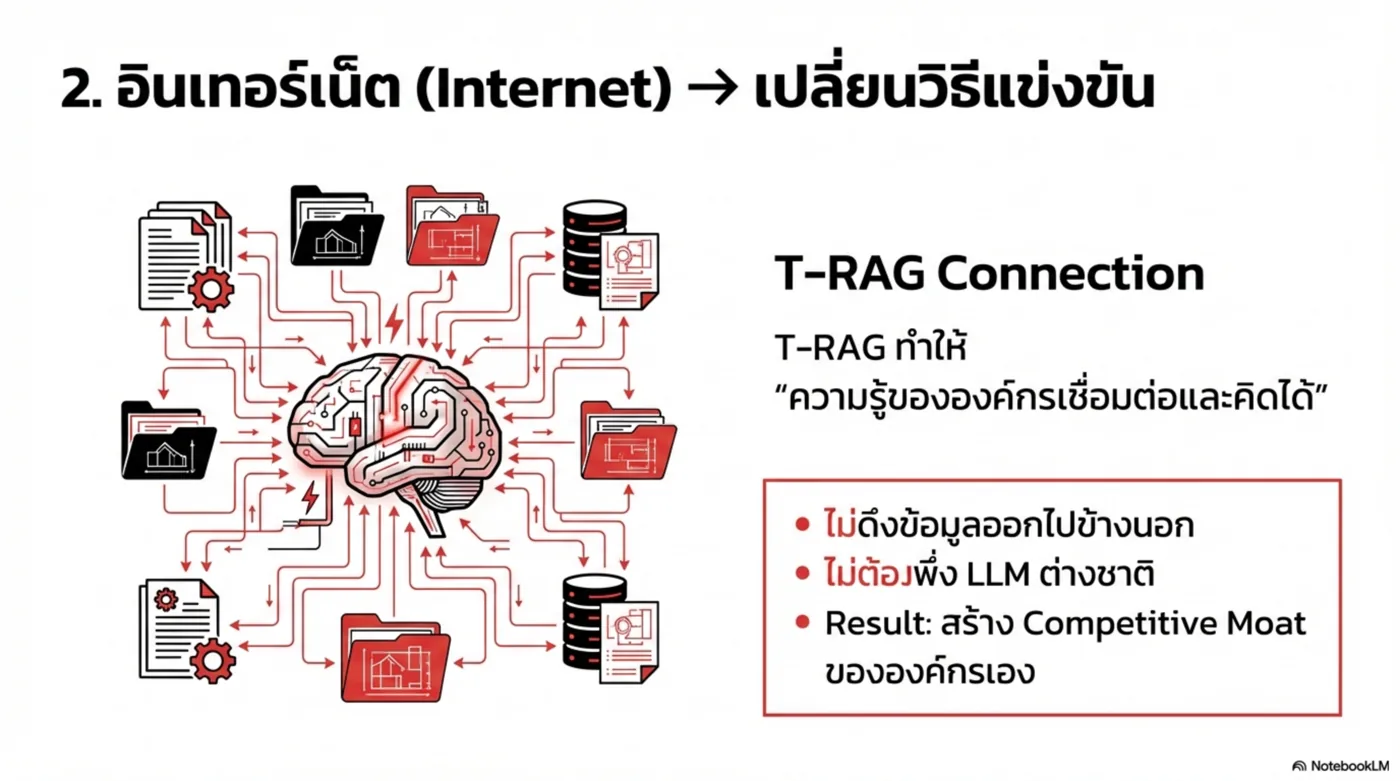
T-RAG Enterprise AI Infrastructure คือแพลตฟอร์มที่ทำให้องค์กร “เชื่อมความรู้–เข้าใจเอกสาร–ตัดสินใจได้” แบบองค์กรจริง: มี Governance, Auditability, และตัวเลือกติดตั้ง (On-Prem / Private Cloud / Cloud) ตามนโยบายข้อมูล
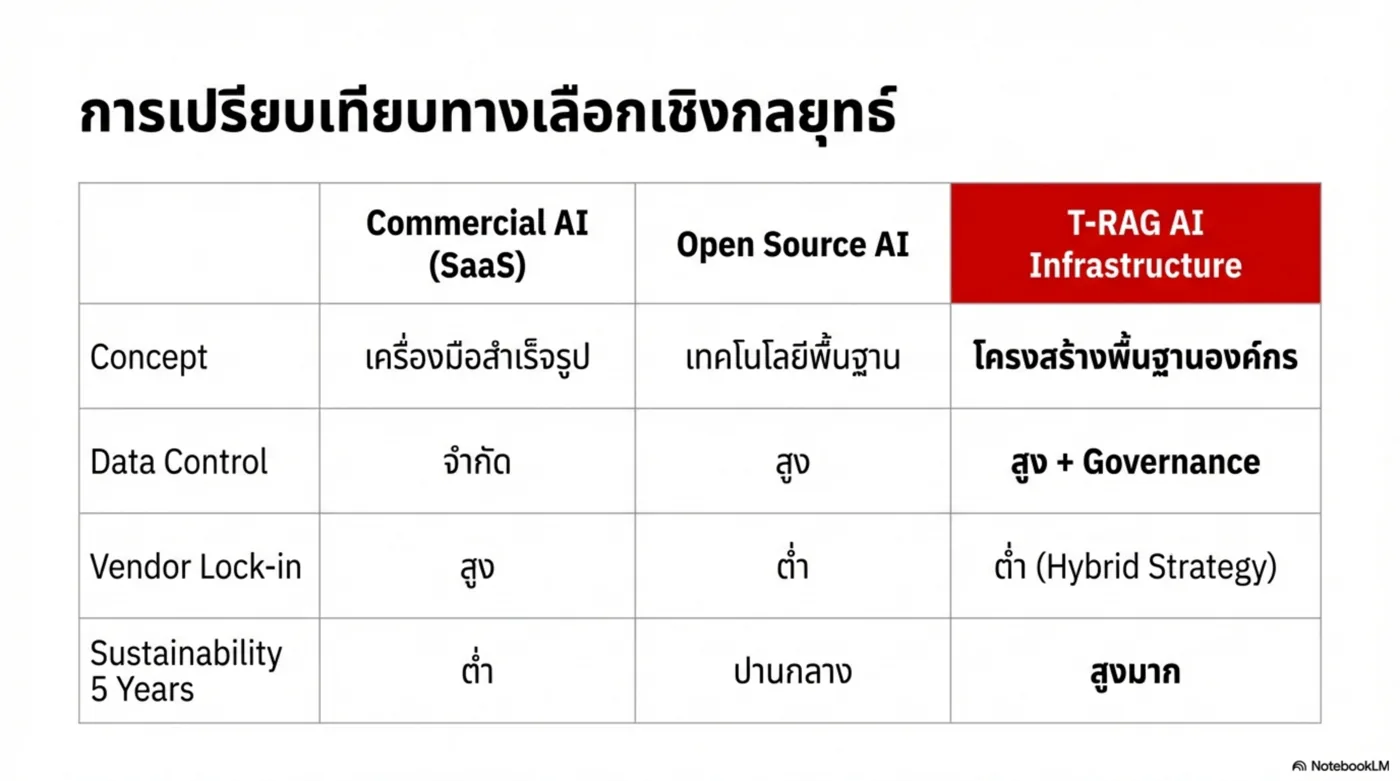



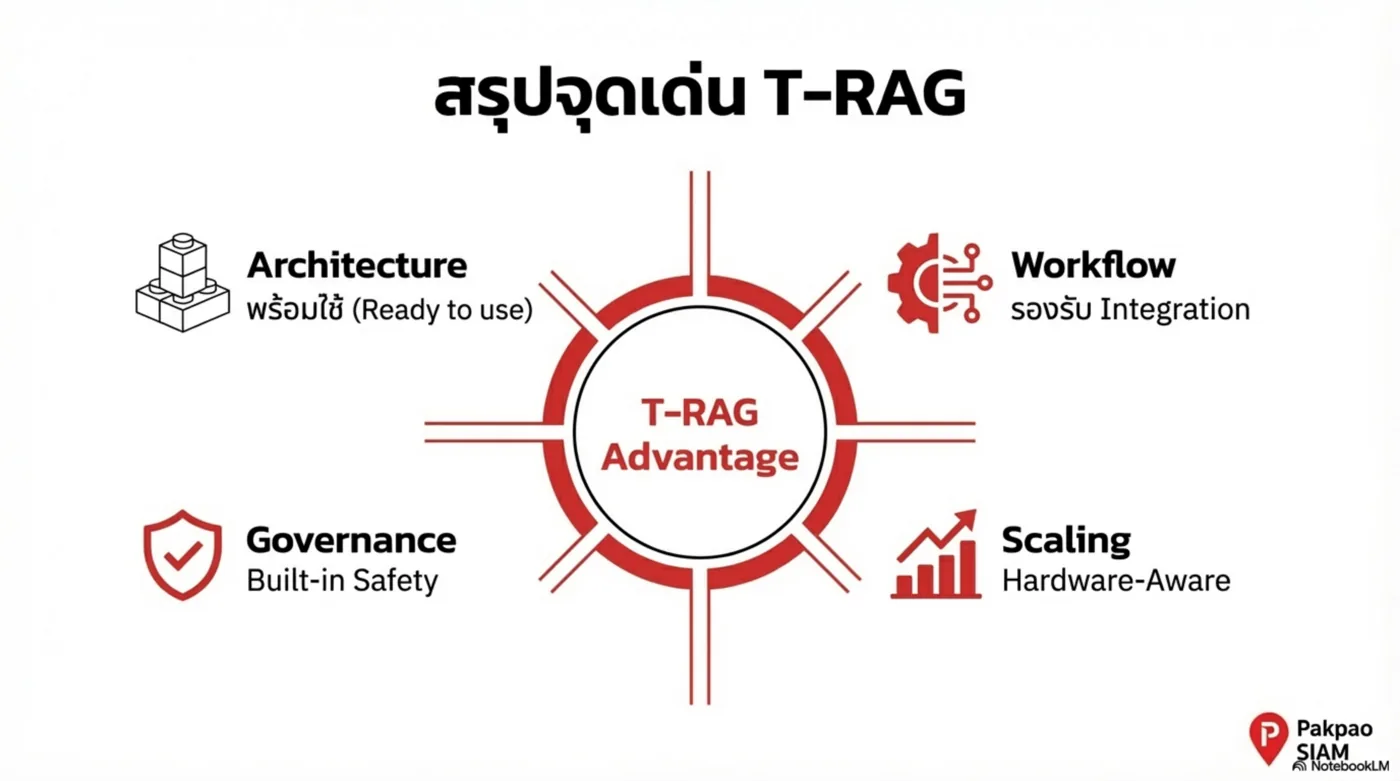
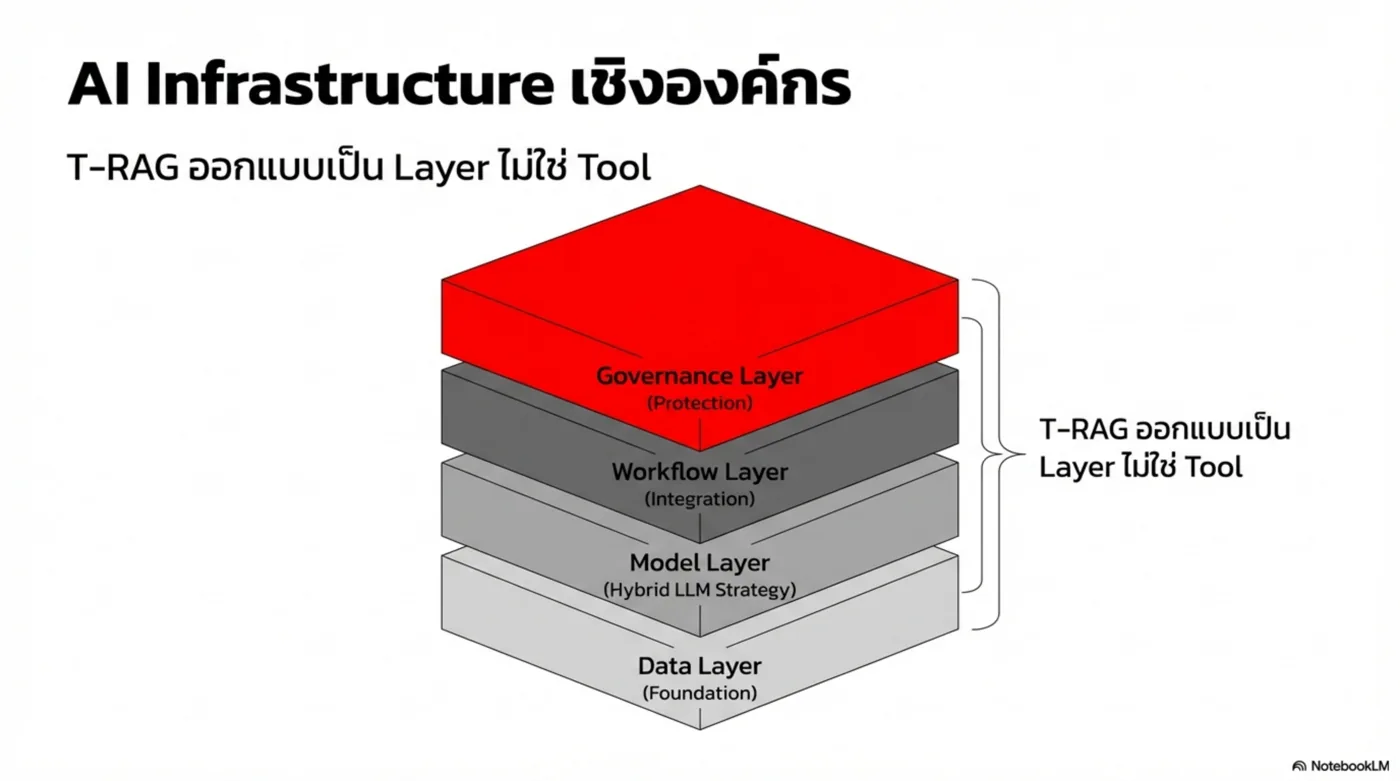
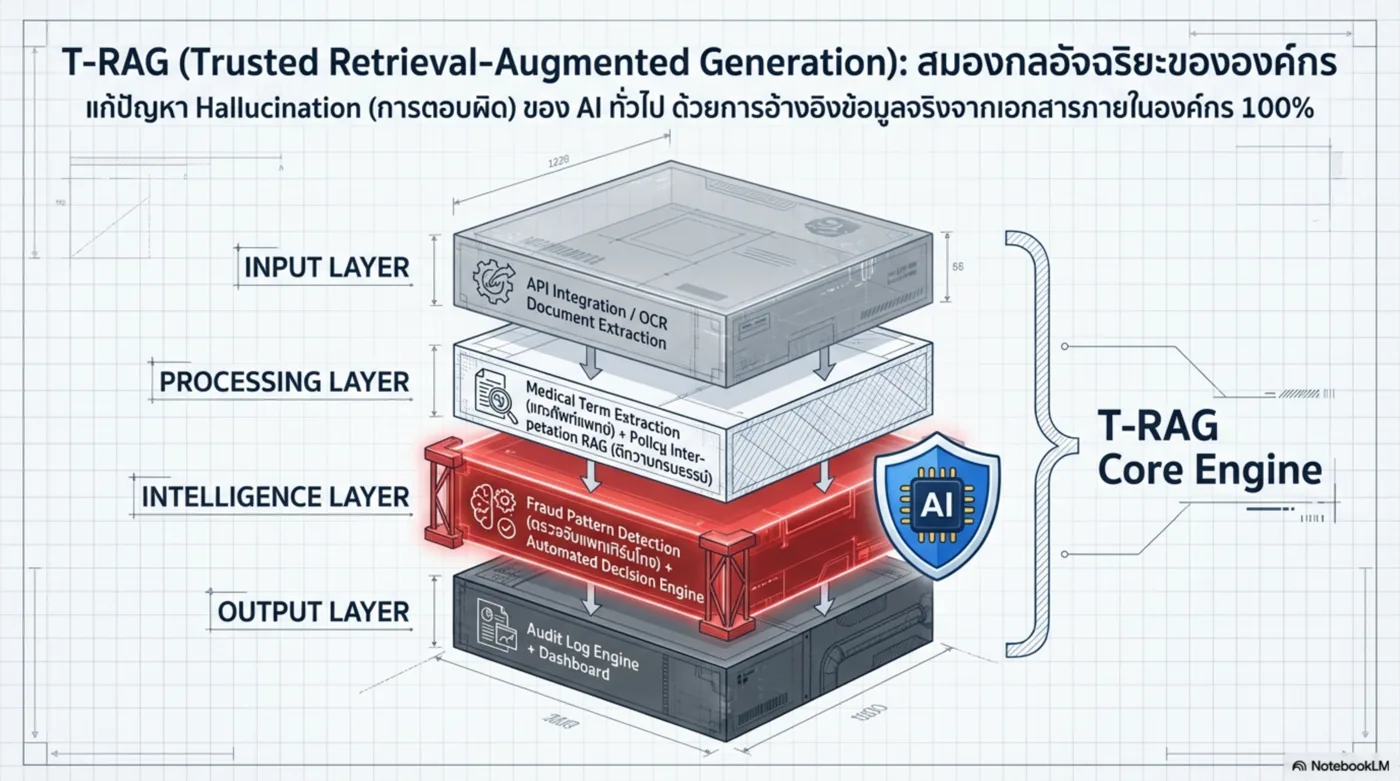
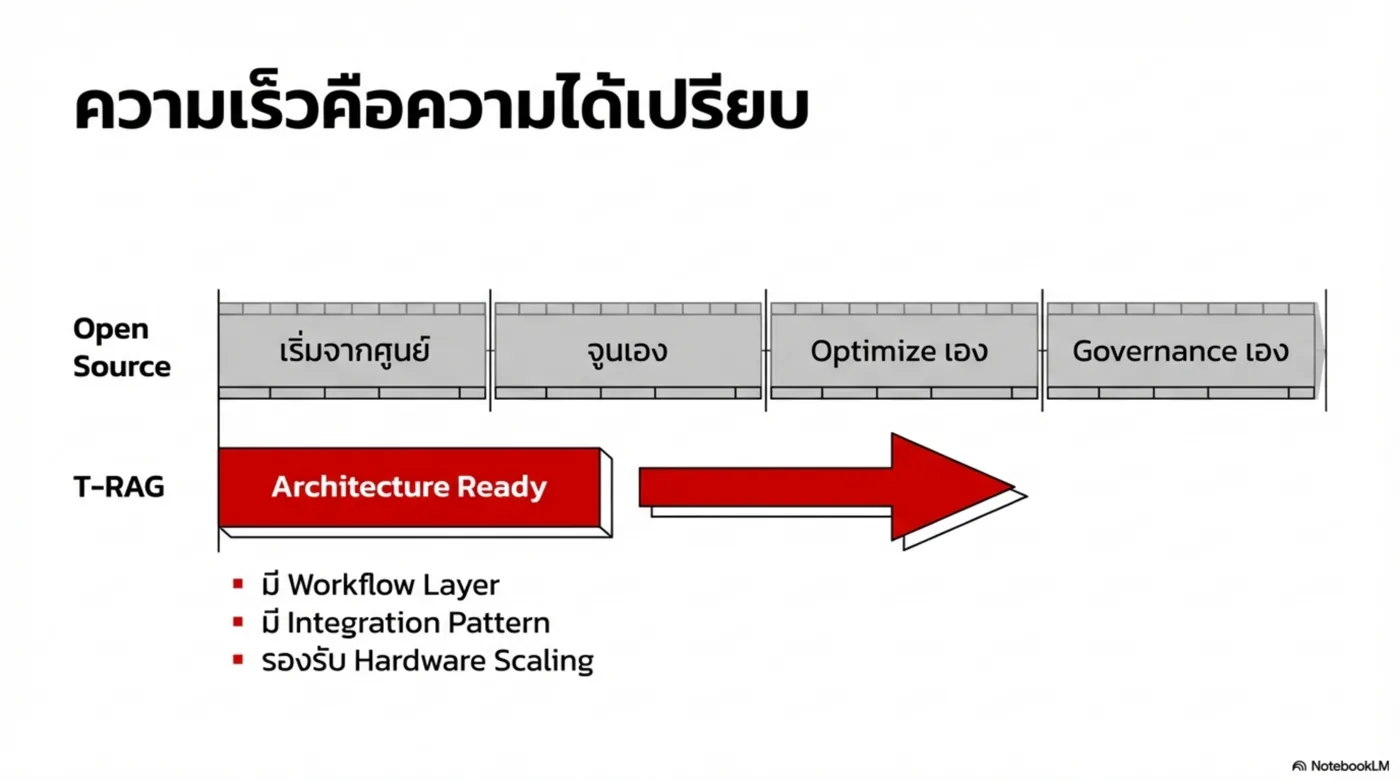

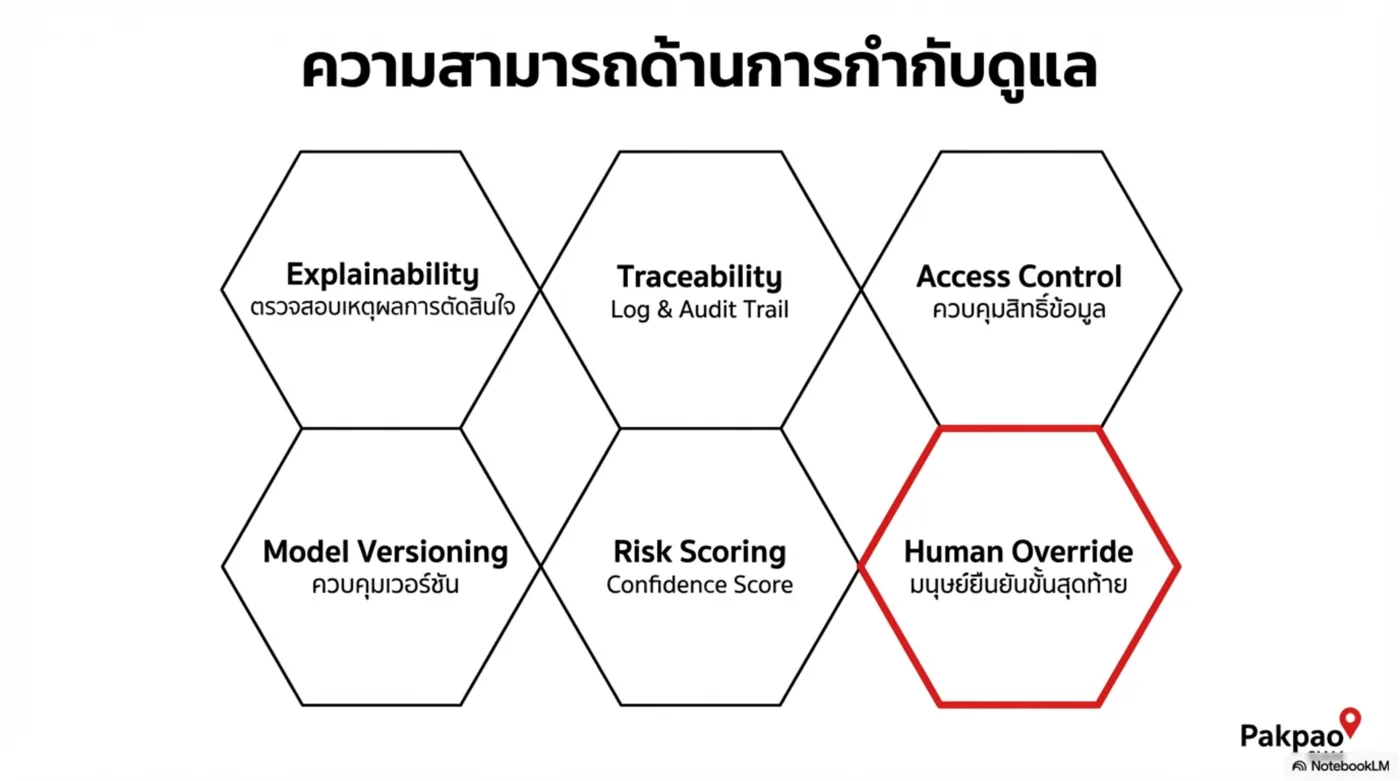
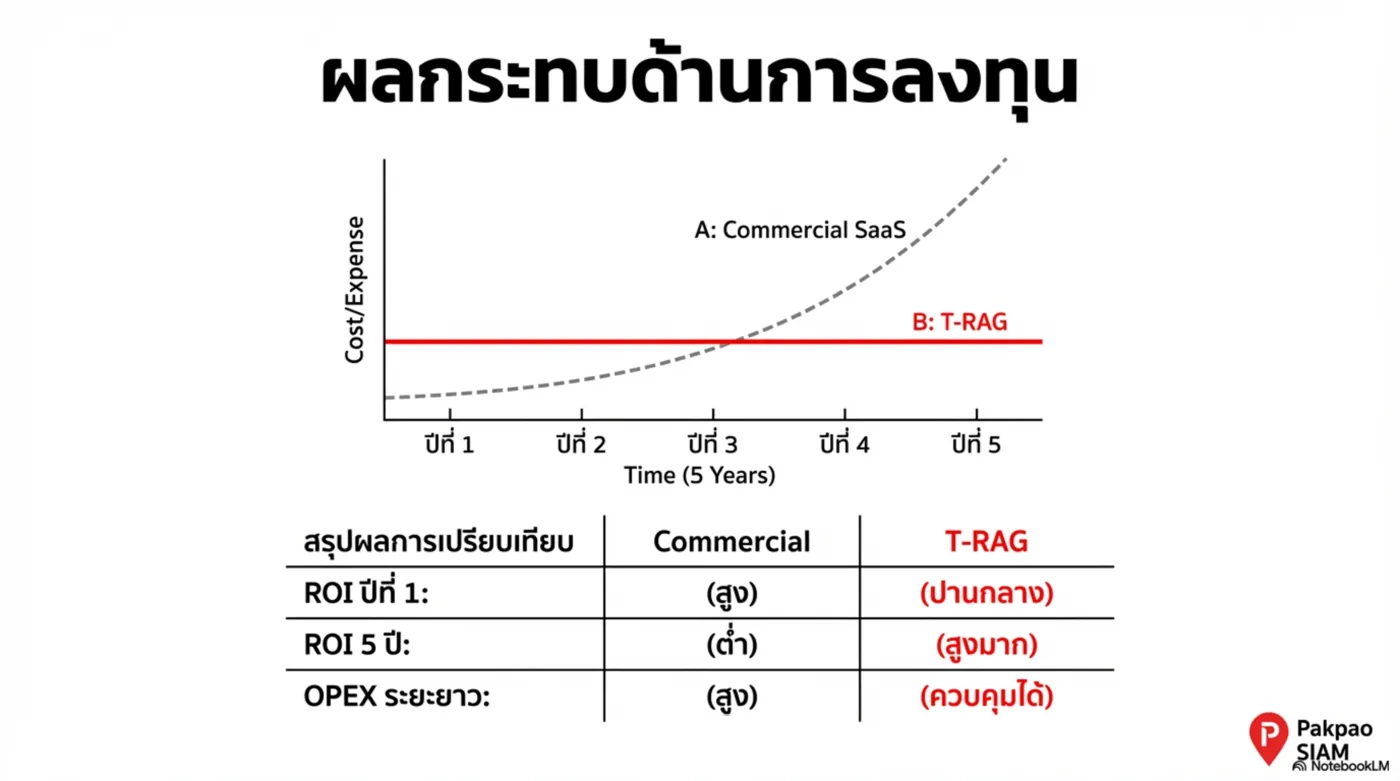
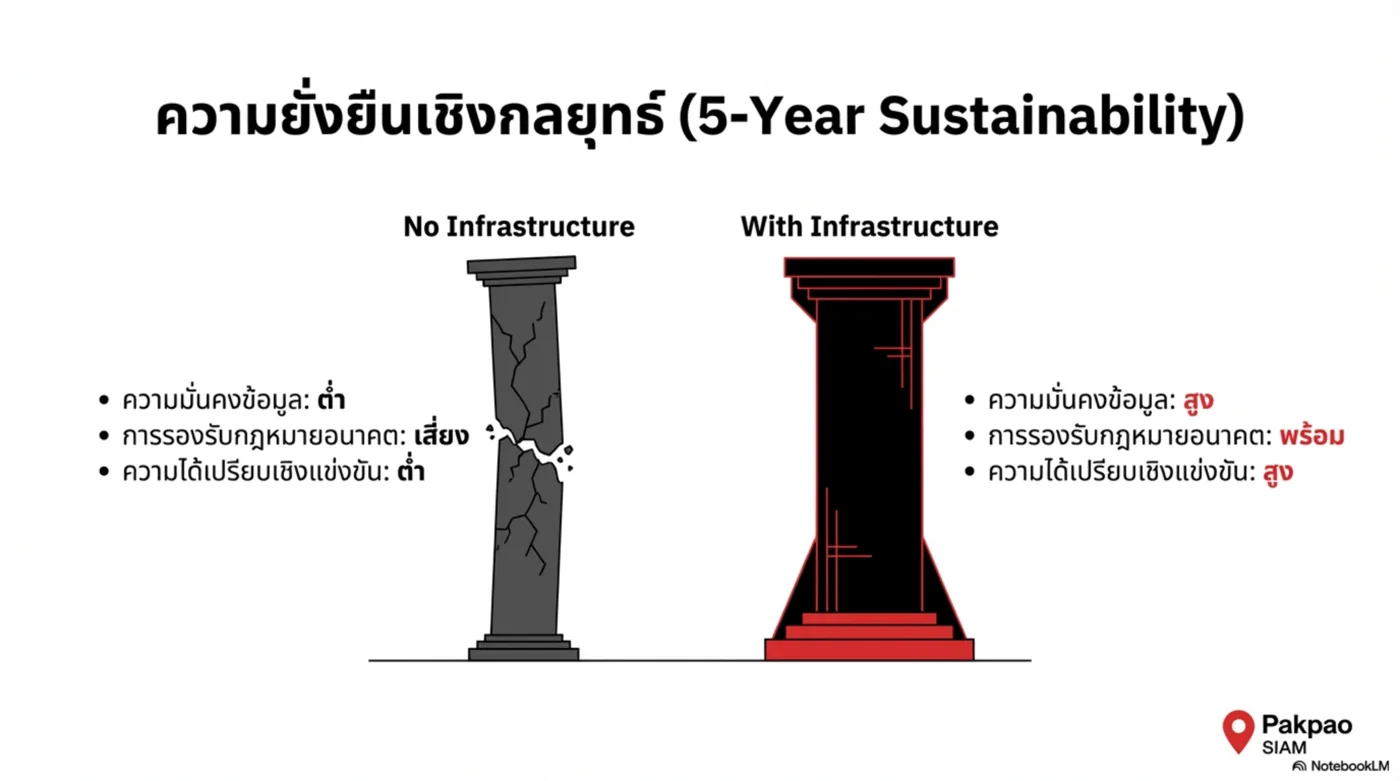
Platform Thesis — จาก Tool สู่ Infrastructure
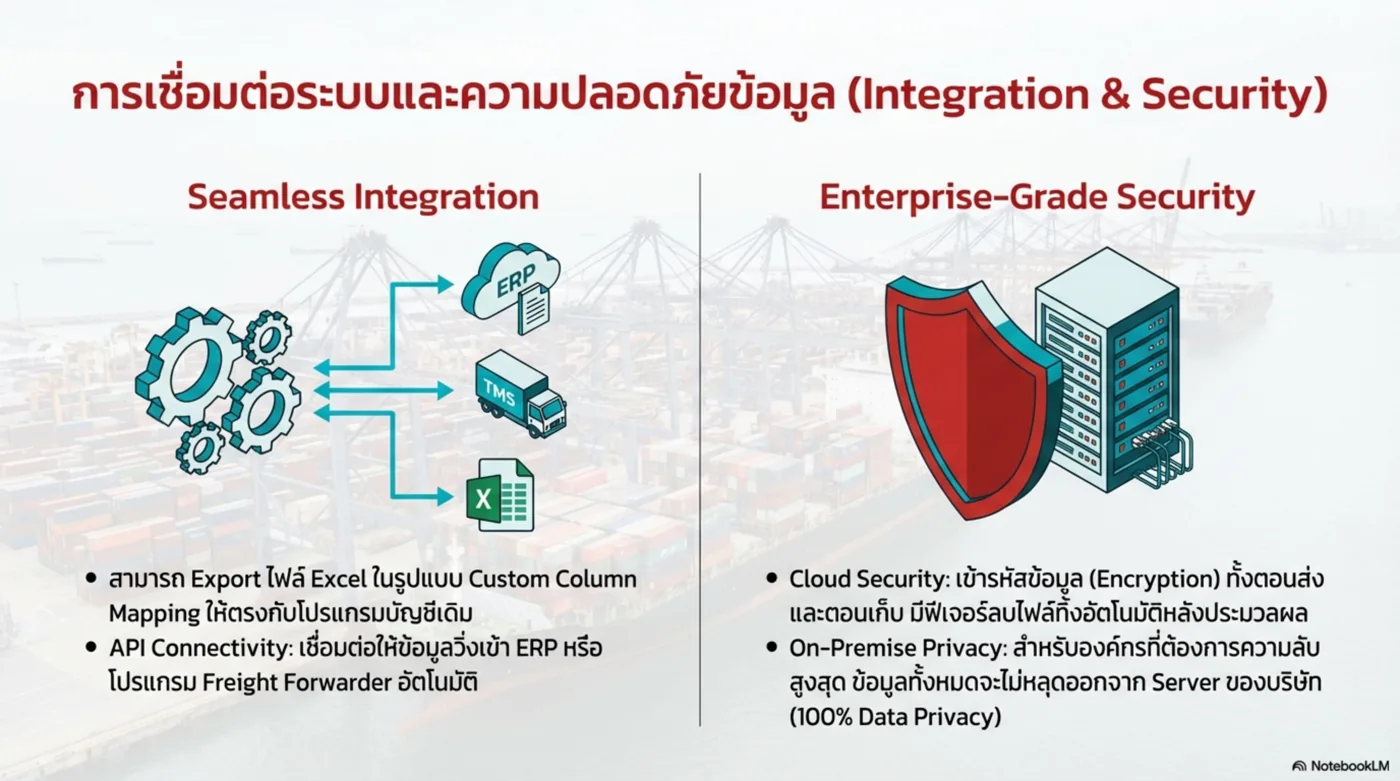
องค์กรไม่ได้ต้องการ “แชตบอทสวย ๆ” แต่ต้องการ ระบบที่ควบคุมความเสี่ยงได้ และ เชื่อมกับกระบวนการทำงานจริง: ข้อมูลอยู่ในองค์กร, มีการอ้างอิง, ตรวจสอบได้, และทำงานร่วมกับ ERP/DB/Workflow ได้
Core Engine
- Ingestion รองรับไฟล์/ฐานข้อมูล/ระบบเดิม
- Hybrid Retrieval (keyword + vector) ลดพลาด “คำสำคัญ”
- Re-ranking ยกคุณภาพผลค้นให้ “เกี่ยวจริง”
- Citations มีที่มา ลด Hallucination
- Policy Layer จำกัดสิทธิ์และขอบเขตความรู้ตาม role
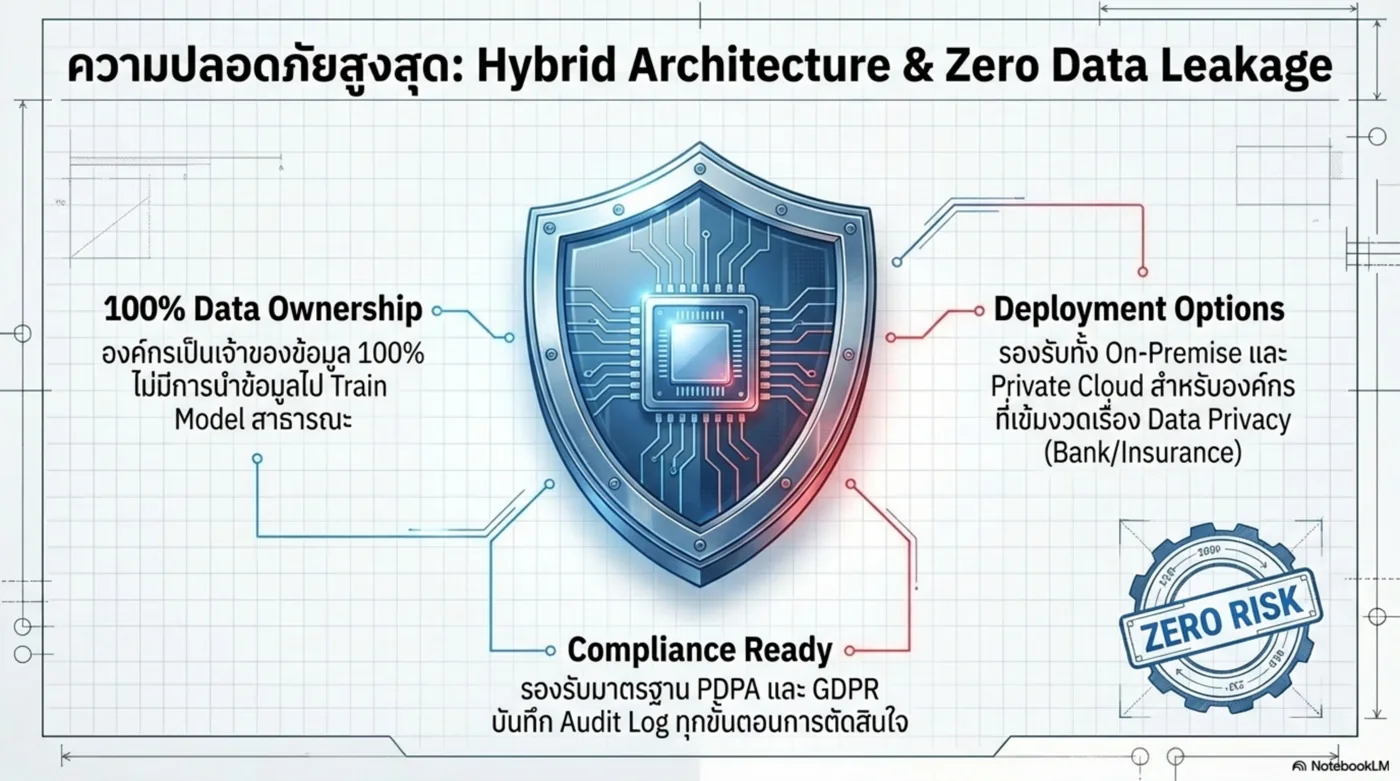
Enterprise Layer
- SSO / RBAC คุมสิทธิ์ผู้ใช้
- Audit Trail ตรวจย้อนหลังได้
- Human-in-the-Loop เคสเสี่ยงให้คนยืนยัน
- Analytics วัด adoption / ROI / knowledge gaps
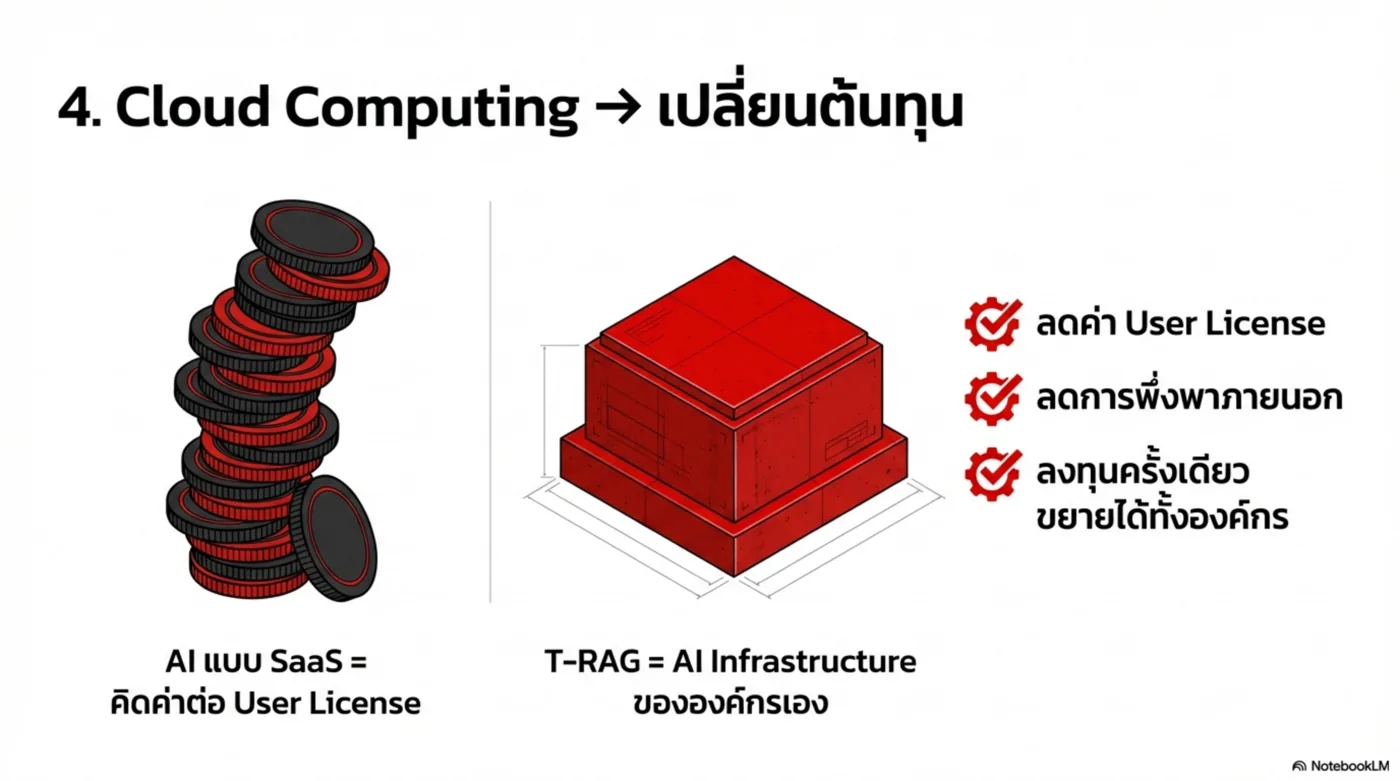
- Deployment Cloud / Private / On-Prem
Product Suite — 5 Solutions บนแกน Infrastructure เดียว
ทั้งหมดแชร์ “Core Engine + Governance” เดียวกัน ทำให้ขยาย use case ได้เร็วและคุมความเสี่ยงได้เหมือนกันทุกระบบ

1) T-RAG Enterprise Brain
มันสมององค์กร: เชื่อมเอกสาร/ข้อมูล/นโยบาย ให้ตอบ “มีหลักฐาน” และบริหารความรู้ได้จริง
- Knowledge Hub + Q&A แบบอ้างอิง
- Tree-Structure RAG สำหรับ reasoning หลายชั้น
- Executive dashboard

2) Autonomous TPA / Claim AI
End-to-End: อ่านเอกสาร → เข้าใจเงื่อนไข → ประเมินความเสี่ยง → ตัดสินใจ → บันทึกตรวจสอบ
- READ → UNDERSTAND → PROTECT → DECIDE
- Fraud signal + confidence scoring
- Workflow + SLA + Audit

3) Corporate HealthShield™
Self-Insurance + NCD Remission เพื่อลดความเสี่ยงระยะยาวขององค์กร
- Remission AI (NCD)
- AI Vision ตรวจภาพอุปกรณ์/ผลตรวจ
- Executive Health Dashboard

4) Financial Document Automation
Ingest → Extract → Validate → ERP Integration แบบองค์กร
- Line-item extraction
- Vendor/master mapping
- Audit-ready trail

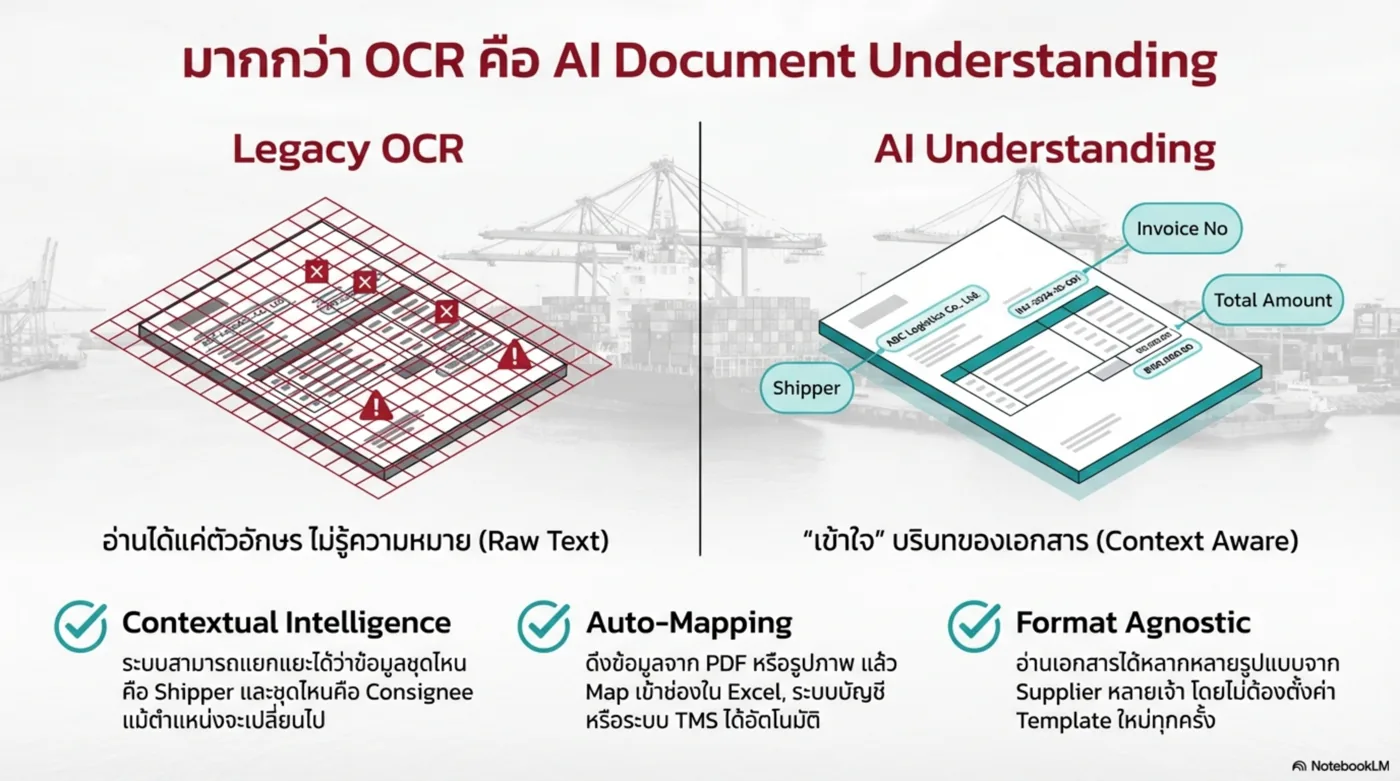
5) Logistics Document Automation
เข้าใจเอกสารนำเข้า-ส่งออก ลด bottleneck และลด human error
- Format-agnostic
- Export Excel / JSON / API
- รองรับ High season scale

Investor Angle — Moat & Why Now
“สงครามข้อมูล” ทำให้องค์กรต้องการ AI ที่ ปลอดภัย, ตรวจสอบได้, และ เชื่อมกระบวนการจริง มากกว่าโมเดลพูดเก่ง
Competitive Moat
- Governance-first: explainability, audit trail, human override
- Infrastructure DNA: reuse engine ขยาย use case ได้เร็ว
- Thai enterprise ready: โครงสร้างและภาษาธุรกิจไทย
- Deployment flexibility: ลด vendor lock-in
Value to CFO / COO
- ลดต้นทุนกระบวนการ จากงานซ้ำ/งานมือ
- ลดความเสี่ยง จากคำตอบมั่ว/ข้อมูลรั่ว/การตรวจสอบไม่ได้
- เพิ่มความเร็ว ในการตัดสินใจและออกบริการ
- วัดผลได้ ผ่าน dashboard & operational KPIs

Roadmap — จาก Pilot สู่ Autonomous Enterprise
แนวทางพัฒนาในอนาคตคือ “ทำให้ AI เข้าไปอยู่ในทุก workflow” อย่างปลอดภัย: มี Industry Packs, Continuous Learning จากการ verify, และ dashboard เชิงผู้บริหาร
Phase 1 — Foundation
- Connect data + ingestion pipeline
- Define governance + policies
- Quick win use cases
Phase 2 — Intelligence
- Scoring & decision logic
- Human-in-the-loop optimization
- Automation expansion
Phase 3 — Autonomous
- End-to-end autonomous workflows
- Predictive analytics
- Hardware-aware scaling